


关键词提取就是从文本里面把跟这篇文章意义最相关的一些词语抽取出来。这个可以追溯到文献检索初期,关键词是为了文献标引工作,从报告、论文中选取出来用以表示全文主题内容信息的单词或术语,在现在的报告和论文中,我们依然可以看到关键词这一项。因此,关键词在文献检索、自动文摘、文本聚类/分类等方面有着重要的应用,它不仅是进行这些工作不可或缺的基础和前提,也是互联网上信息建库的一项重要工作。
基于tfidf和textrank关键字提取")
关键词抽取从方法来说主要有两种:
目前大多数应用领域的关键词抽取算法都是基于后者实现的,从逻辑上说,后者比前者在实际应用中更准确。
下面介绍一些关于关键词抽取的常用和经典的算法实现。
在信息检索理论中,TF-IDF 是 Term Frequency - Inverse document Frequency 的简写。TF-IDF 是一种数值统计,用于反映一个词对于语料中某篇文档的重要性。在信息检索和文本挖掘领域,它经常用于因子加权。TF-IDF 的主要思想就是:如果某个词在一篇文档中出现的频率高,也即 TF 高;并且在语料库中其他文档中很少出现,即 DF 低,也即 IDF 高,则认为这个词具有很好的类别区分能力。
TF 为词频(Term Frequency),表示词 t 在文档 d 中出现的频率,计算公式:
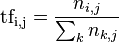
其中,ni,j 是该词 ti 在文件 dj 中的出现次数,而分母则是在文件 dj 中所有字词的出现次数之和。
IDF 为逆文档频率(Inverse document Frequency),表示语料库中包含词 t 的文档的数目的倒数,计算公式:
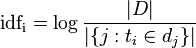
其中, 表示语料库中的文件总数,|{j:ti∈dj}| 包含词 ti 的文件数目,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用 1+|{j:ti∈dj}|。
TF-IDF 在实际中主要是将二者相乘,也即 TF * IDF, 计算公式:
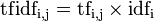
因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。例如,某一特定文件内的高频率词语,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的 TF-IDF。
好在 jieba 已经实现了基于 TF-IDF 算法的关键词抽取,通过命令 引入,函数参数解释如下:
接下来看例子,我采用的语料来自于百度百科对人工智能的定义,获取 Top20 关键字,用空格隔开打印:
人工智能 智能 2017 机器 不同 人类 科学 模拟 一门 技术 计算机 研究 工作 Artificial Intelligence AI 图像识别 12 复杂 流行语
下面只获取 Top10 的关键字,并修改一下词性,只选择名词和动词,看看结果有何不同?
[('人工智能', 0.9750542675762887), ('智能', 0.5167124540885567), ('机器', 0.20540911929525774), ('人类', 0.17414426566082475), ('科学', 0.17250169374402063), ('模拟', 0.15723537382948452), ('技术', 0.14596259315164947), ('计算机', 0.14030483362639176), ('图像识别', 0.12324502580309278), ('流行语', 0.11242211730309279)]
TextRank 是由 PageRank 改进而来,核心思想将文本中的词看作图中的节点,通过边相互连接,不同的节点会有不同的权重,权重高的节点可以作为关键词。这里给出 TextRank 的公式:
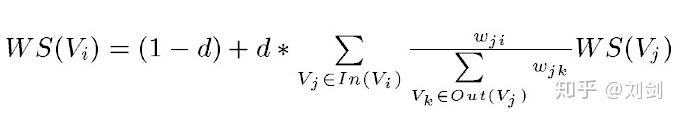
节点 i 的权重取决于节点 i 的邻居节点中 i-j 这条边的权重 / j 的所有出度的边的权重 * 节点 j 的权重,将这些邻居节点计算的权重相加,再乘上一定的阻尼系数,就是节点 i 的权重,阻尼系数 d 一般取 0.85。
TextRank 用于关键词提取的算法如下:
(1)把给定的文本 T 按照完整句子进行分割,即:
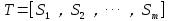
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,其中 ti,j 是保留后的候选关键词。
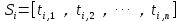
(3)构建候选关键词图 G = (V,E),其中 V 为节点集,由(2)生成的候选关键词组成,然后采用共现关系(Co-Occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为 K 的窗口中共现,K 表示窗口大小,即最多共现 K 个单词。
(4)根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
(6)由(5)得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
同样 jieba 已经实现了基于 TextRank 算法的关键词抽取,通过命令 引用,函数参数解释如下:
直接使用,接口参数同 TF-IDF 相同,注意默认过滤词性。
接下来,我们继续看例子,语料继续使用上例中的句子。
智能 人工智能 机器 人类 研究 技术 模拟 包括 科学 工作 领域 理论 计算机 年度 需要 语言 相似 方式 做出 心理学
如果修改一下词性,只需要名词和动词,看看结果有何不同?
智能 人工智能 机器 人类 技术 模拟 包括 科学 理论 计算机 领域 年度 需要 心理学 信息 语言 识别 带来 过程 延伸
语料是一个关于汽车的短文本,下面通过 Gensim 库完成基于 LDA 的关键字提取。整个过程的步骤为:文件加载 -> jieba 分词 -> 去停用词 -> 构建词袋模型 -> LDA 模型训练 -> 结果可视化。
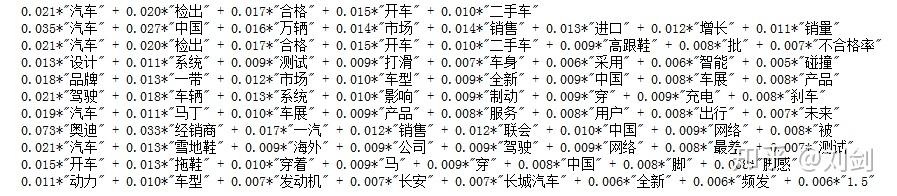
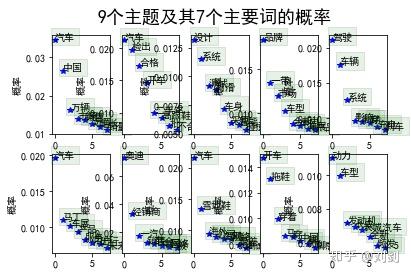
除了 jieba,也可以选择使用 HanLP 来完成关键字提取,内部采用 TextRankKeyword 实现,语料继续使用上例中的句子。
本文地址:http://lianchengexpo.xrbh.cn/quote/11310.html 迅博思语资讯 http://lianchengexpo.xrbh.cn/ , 查看更多