ictclas官方版是一款功能强大的分词系统。ictclas最新版支持中文分词、词性标注、命名实体识别、新词识别、用户词典等功能,能够帮助用户进行汉语言词法的分析研究。ictclas软件还为用户提供了词性标准、关键词提取、接口扩展等功能,满足不同用户的需求。

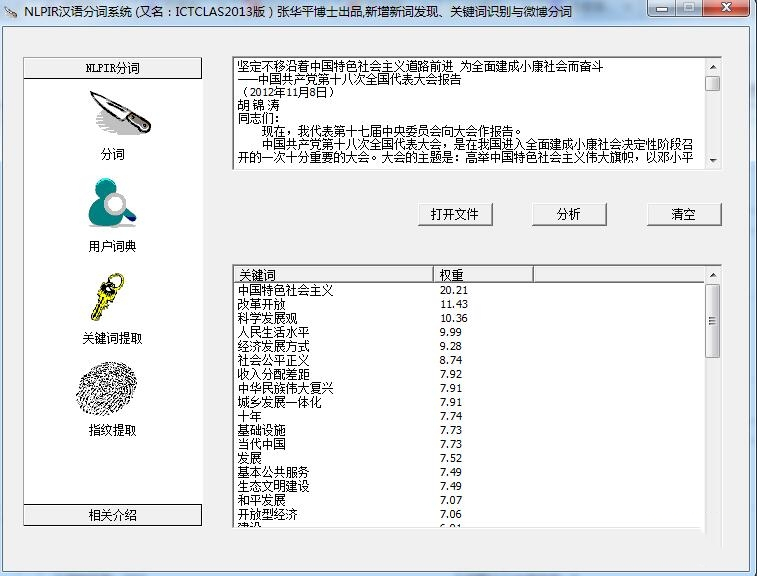 ictclas软件介绍
ictclas软件介绍
中国科学院计算技术研究所在多年研究工作积累的基础上,研制出了汉语词法分析系统ICTCLAS(InstituteofComputingTechnology,ChineseLexicalAnalysisSystem),主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。我们先后精心打造五年,内核升级7次,目前已经升级到了ICTCLAS2009用户词典接口扩展用户可以动态增加、删除用户词典中的词,调节分词的效果。提高了用户词典使用的灵活性。
ICTCLAS词法分析系统,从2009年开始,为了和以前工作进行大的区隔,并推广NLPIR自然语言处理与信息检索共享平台,调整命名为NLPIR分词系统。张华平博士先后倾力打造十余年,内核升级十余次,先后获得了2010年钱伟长中文信息处理科学技术奖一等奖,2003年国际SIGHAN分词大赛综合第一名,2002年国内973评测综合第一名。全球用户突破30万,包括中国移动、华为、中搜、3721、NEC、中华商务网、硅谷动力、云南日报等企业,清华大学、新疆大学、华南理工、麻省大学等机构:同时,ICTCLAS广泛地被《科学时报》、《人民日报》海外版、《科技日报》等多家媒体报道。您可以访问Google进一步了解ICTCLAS的应用情况。
ictclas软件功能
1.指纹提取
根据文章的内容,结构,词语间的关系,分析出能够表示该文章的语义指纹,使用数字序列表示。
2.分词粒度可调
可以控制分词结果的粒度。共享版本提供两种分词粒度,标准粒度和粗粒度,满足不同用户的需求。
3.用户词典接口扩展
用户可以动态增加、删除用户词典中的词,调节分词的效果。提高了用户词典使用的灵活性。
4.词性标注功能加强
多种标注级的选择,系统可供选择的标注级有:计算所一级标注级,计算所二级标注集,北大一级标注集,北大二级标注集。
5.关键词提取
自动抽取出能很好地代表文档主题的若干个词或短语。关键词抽取技术广泛应用于信息检索、文本分类/聚类、信息过滤、文档摘要等各种智能文本信息处理领域,具有很好的应用价值。
6.新词发现与自适应分词功能
从较长的文本内容中,基于信息交叉熵自动发现新特征语言,并自适应测试语料的语言概率分布模型,实现自适应分词。
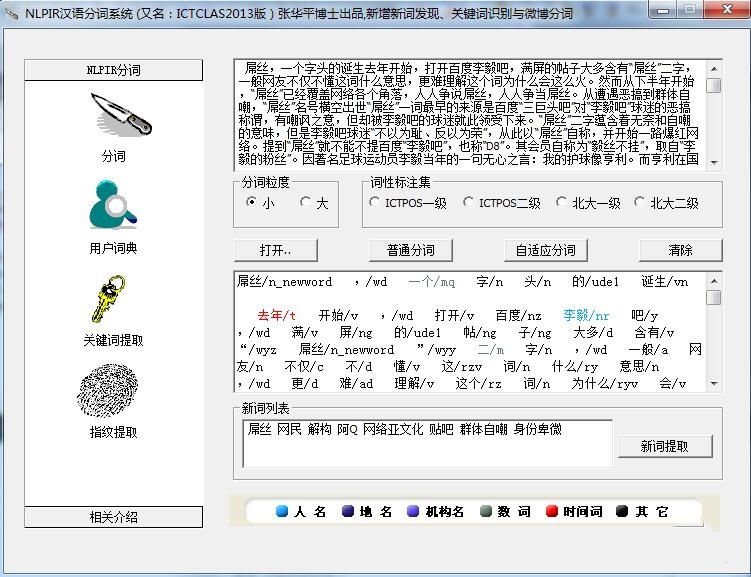 ictclas软件优势
ictclas软件优势
一、国内和国际权威的公开评测、三万客户的认可
有些公司为了商业目的,关门自测,自称准确度99.50%,没有介绍测试环境和测试方法,封闭测试或者小规模的开放测试准确度100%都不足为奇的,ICTCLAS1.0在国内973专家组组织的评测中活动获得了第一名,ICTCLAS2.0在第一届国际中文处理研究机构SigHan组织的评测中都获得了多项第一名,具体的参见系统评测部分。这些都是权威机构进行大规模现场开放测试的结果,真实可信。
ICTCLAS已经向国内外的企业和学术机构颁发了30,000多份授权,其中包括3721、NEC、中华商务网、硅谷动力、云南日报等企业,新疆大学、清华大学、华南理工、麻省大学;同时,ICTCLAS广泛地被《科学时报》、《人民日报》海外版、《科技日报》等多家媒体报道。您可以访问Google进一步了解ICTCLAS的应用情况。
二、综合性能最优
分词系统能否达到实用性要求主要取决于两个因素:分词精度与分析速度,这两者相互制约,难以平衡。大多数系统往往陷入“快而不准,准而不快”的窘境。我们研制出了完美PDAT大规模知识库管理技术,在高速度与高精度之间取得了重大突破,该技术可以管理百万级别的词典知识库,单机每秒可以查询100万词条,而内存消耗不到知识库大小的1.5倍。基于该技术,ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器。
三、统一的语言计算理论框架
汉语分词牵涉到汉语分词、未定义词识别、词性标注以及语言特例等多个因素,大多数系统缺乏统一的处理方法,往往采用松散耦合的模块组合方式,最终模型并不能准确有效地表达千差万别的语言现象,而ICTCLAS采用了层叠隐马尔可夫模型(Hierarchical
Hidden Markov
Model),将汉语词法分析的所有环节都统一到了一个完整的理论框架中,获得最好的总体效果,相关理论研究发表在顶级国际会议和杂志上,从理论上和实践上都证实了该模型的先进性。
四、全方位支持各种环境下的应用开发
ICTCLAS全部采用C/C++编写,支持Linux、FreeBSD及Windows系列操作系统,支持C/C++/C#/Delphi/Java等主流的开发语言。
五、应需而变,量身定做
所有功能模块均可拆卸组装,ICTCLAS有GB2312和BIG5版本,可分别处理目简繁体中文;支持当前广泛承认的分词和词类标准,包括计算所词类标注集ICTPOS3.0,北大标准、滨州大学标准、国家语委标准、台湾“中研院”、香港“城市大学”;用户可以直接自定义输出的词类标准,定义输出格式;用户可以根据自己的需求,进行量身自助式定做适合自己的分词系统。
ictclas更新日志
本文地址:http://lianchengexpo.xrbh.cn/quote/12571.html
迅博思语资讯 http://lianchengexpo.xrbh.cn/ , 查看更多


