


随着深度学习在微博业务场景中的广泛使用,深度学习平台也遇到一些挑战:在离线训练方面,各业务方需求丰富多样,任务管理纷繁复杂,大数据与大模型带来训练时长的压力;在线推理方面,基于模型服务的特殊性,如何在满足微博大流量高性能的在线业务需求同时,保证服务的高可用与稳定性。新浪微博基于K8s构建了分布式离线与在线方案,解决了上述两个维度遇到的挑战。 新浪微博机器学习研发架构师于翔老师在ArchSummit全球架构师峰会2018北京站分享了《微博深度学习平台基于 K8s 的解决方案》主题演讲,介绍了微博深度学习平台概况,以及他们在离线与在线两个维度基于 K8s 的应用实践,我们对演讲内容进行了整理,希

微博的深度学习平台服务于微博的实际信息流业务。我们对当前业务做了汇总,简单来讲,按照业务背景主要分为两类:
第一类是多媒体的内容理解,这也是深度学习应用比较多的一个领域,主要包括图片、视频、音频等维度的算法应用。业务应用列举的比较多,这里以智能裁剪为例,简单说一下,对于全身的人像照片,生成缩略图时,如果没有做特殊处理,可能会生成到人身的中间部位,这张缩略图就会显得比较诡异;智能裁减主要做得事情,就是基于人脸检测找到人脸位置,根据人脸位置生成缩略图。
第二类是在 CTR 任务,在做 CTR 排序时,我们常常主要使用特征工程加上传统的机器学习模型,像 LR/FM 这样的模型。这种方式下特征工程的成本会比较高,总结来说可以归纳为复杂特征简单模型模式。与之对应的,便是简单特征复杂模型的模式,把复杂的特征处理和特征组合,以及高阶的特征组合隐含到模型里面去,深度学习便是这一模式的典型代表;现在关于这方面的模型也比较多,包括 Wide&Deep、DeepFM、DeepCross 等等。
注意!注意!!阿里云开发者成长计划正式启动啦,该计划面向全年龄段开发者!!
免费资源、免费体验、免费学习、免费实践 4 大场景,帮助开发者轻松掌握云上技能,助推成长,成就云计算技术人才~
上开发者成长计划的车,一起来学习叭,风里雨里阿里等你!!
传送门在这里:https://developer.aliyun.com/plan/promotion/1?spm=a1z389.11499242.0.0.65452413zGOcUM&utm_content=g_1000199577
添加阿里妹官微(alimei6)备注【阿里技术】,即可领取Python、Java、数据库、运维等等阿里独家学习资料和福利!票圈还有更多阿里校招社招资讯、免费训练营和大佬干货直播等等等分享!不断更新中~阿里妹这里等你!
在算法应用中,将算法落地到实际生产环境还有很多环节要处理。这里以微博的深度学习工作流为例,它是基于微博的实际业务,主要分为离线和在线两条流程。
离线流程经过数据处理,生成原始样本,各业务方根据需求进行特征处理,生成模型的训练样本,然后进入模型训练的环节,各业务选取算法进行模型的训练和迭代,评估这个模型可用之后,将它部署到生产环境,这就是离线的部分。
在线流程也是一一对应的,在线的样本数据经过特征处理,特征处理与离线使用同一套配置文件,以保证一致性与正确性。经过模型预测得到预估值,然后业务根据预估值,再去做一些相应的排序与处理,这是在线部分。
K8s 在这里的应用主要是模型训练和模型预测两个环节,后面会具体展开讲。大家可以看到整个工作流环节比较多,除了模型训练,还有模型部署、样本生成、模型部署等许多环节,深度学习平台的目标是为业务提供一站式的工作流服务,让业务不用关心底层烦琐的工程细节,比如资源的调度、GPU 的分配细节等等,专注于算法和效果的调优。
图 2 显示的是深度学习平台的整体架构,主要分为算法、存储、计算、调度还有资源。在算法方面,算法又分为算法训练和算法服务,算法训练主要是样本的处理和数据处理,模型训练和评估流程,这一部分是基于 weilearn 计算框架来实现;算法服务主要是在线的特征查询、模型服务。另外,平台目前也在做端上内容生成的业务需求:比如图片风格化,给你一张目标图片,生成跟目标图片一样风格的图片,这里有一个端上引擎。最后,对于成熟的 CTR 任务它需要一个迭代的更新上线的系统机制,这部分目前基于 K8s 和 weiflow ,实现了一套持续训练持续部署的方案。调度这方面目前主要用 Yarn 和 K8s ,这是深度学习平台架构。
背景
接下来介绍一下离线训练。随着接入的业务方越来越多,平台面临的问题逐渐暴露出来,简单总结了一下,从两个角度来看。
首先是从业务角度,业务接入门槛高。刚才提到了微博业务模式有 CTR 排序,多媒体内容理解,还有像图片风格化这样的多媒体内容生成。
另外从平台角度去看,平台需要保证稳定性,这里基于不同的粒度做了下总结。分别是任务管理、资源管理,还有集群管理,每个粒度展开去讲内容会比较多,这里简单说几个点:
深度学习训练框架
出于这两点,我们开发了 weilearn 深度学习框架,主要分为这四部分:样本库、训练库、调度计算、模型库。实现业务内容的配置化,比如说你要提交一个任务,只要把参数配置一下,配需要的资源和算法,通过训练框架将它转化成具体的计算任务,通过配置化降低业务的接入成本。另外我们通过统一调度,提高任务的效率和平台稳定性。基于 Yarn 跟 K8s ,跟阿里容器团队合作,使用的 Arena 深度学习训练工具,通过调度提交到集群,训练完之后,把模型放到模型库里。另外,比如像 BERT 这种模型刚出来,每个业务都有自己的需求,自己都想试一下,其实这些任务是重复的,我们就打通了样本库和模型库,实现了模型和样本的共享,通过这种方式避免业务重复造轮子。
分布式 TensorFlow
接下来,基于 TensorFlow 去看分布式遇到的一些问题。首先图 4 显示的是 TensorFlow 的一个集群拓扑模式的发展演变过程:
对于 TensorFlow PS 模式展开讲,其实它的 ParamaterServer 模式可以分为同步和异步,对于同步模式,性能是最大的瓶颈,为了提升性能,TensorFlow 使用了一个 Worker backup 的方式,简单来讲如果我们的集群起了 10 个 Worker,但是真正进行梯度聚合的时候用了 7 个,这样通过丢掉一定的样本数据,在保证同步的训练效果的同时保证性能。ring All reduce 如果细分,除了 MPI 本身的 Allreduce 语义,它还有基于环状的 ring All reduce,还有基于树状的 treeAllreduce。对于分布式策略现在支持的有单机多卡的 mirrored 模式,还有多机多卡的模式。
从这里可以看到,集群拓扑比较复杂,我们的训练系统需要适配各种的模式。
关于 TensorFlow 在分布式训练遇到的一些问题,首先是前面提到的集群拓扑模式繁多,另外对于静态拓扑,需要额外去保证端口不重复,因为静态拓扑需要在集群启动前,明确各个结点的服务发现信息、包括 IP 以及端口号,TensorFlow 并没有帮你管理这些端口,需要自己去管理。另外一个问题就是任务稳定性和状态跟踪,这是分布式计算任务里面基本的需求。此外,TensorFlow 在启动的时候,不论你的机器上有多少张卡,会把机器所有的 GPU 卡占满,这也是一个比较头疼的地方。
K8s 分布式训练的解决方案,我们是基于 Arena 来实现的,关于 Arena,现在阿里云已经开源,大家如果想尝试,可以从网上去下载。图 5 显示的是 Arena 的基础架构,基于 Kubeflow 来做的集成与扩展。
Kubeflow 包括两部分,一个是 ksonnet,另一个是自定义的 Operator,在 Arena 实现时,使用 helm 替代了 ksonnect,在上面又封装了一层 CLI 的接口。回到 TensorFlow ,分布式机制是基于自定义资源对象 TFjob,实现对分布式集群的管理 ,简单来说,当前提交了一个分布式任务后,会生成一个 TFjob 描述文件,自定义控制器 TFoperator 发现 TFJob 后,根据描述文件去起一个分布式任务集群。另外在通信方面,arena 是基于 headless Service 来实现的节点寻址。普通的 Service 如果我们要根据 DNS 寻址,它实际上线找到的是 Service 的 VIP 地址,然后在进行一次路由转发,找到 Pod 对应的地址。而 headless service 在 DNS 寻址时直接 对 Pod 寻址, 跳过了 Service 这层路由转发,会提升一定的性能,Pod 使用的是 Host 的网络,这种方式也保证了集群通讯的性能。
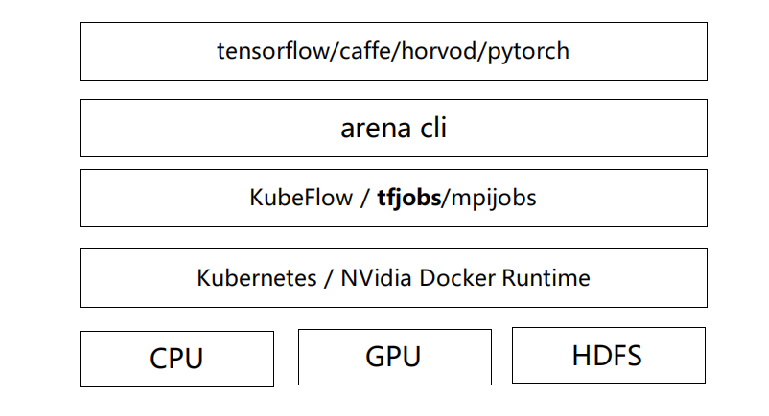
前面讲了基本原理,那 Arena 都做了哪些事情?第一,支持多种集群拓扑,包括 PS、MPI、单机模式,都可以通过 Arena 提交。第二,简化了任务的管理,前面提到到端口分配与资源调度等都是 Arena 去管理,支持多种代码提交方式, rsync 或者 git,这部分是基于 init container 机制实现的,起任务之前先把代码拉到本地去做。第三,TFJob 提供了一个 Dashboard,可以通过这个 Dashboard 看分布式任务的状态和日志。
以上是离线训练框架以及 K8s 的应用,这里看到的是某个图片分类的业务方,在接入平台前后的对比,性能跟效果提升还是比较明显的。
模型训练完成后,就是模型的上线部署。接下来看下模型上线这一部分基于 K8s 做的应用实践。
模型预测,这是深度学习框架重要的环节,因为微博的业务场景需求,对并发量和延时性要求都是比较敏感的,这张图显示的是模型服务的整体框架,主要分为三层。
第一层是集群调度层,模型服务现在线上有 CPU、也有 GPU 的支持,基于一些历史原因,以及业务对机器的特殊需求,这些 CPU 可能有很多型号,包括 8 核、16 核、32 核,GPU 也有 P 系列、M 系列的。基于 K8s 和 Docker 进行了资源的管理和调度,保证业务集群的稳定性。
第二层就是核心架构层,是在线服务和性能提升的关键层,通过统一的版本管理,对模型进行动态加载,保证线上服务更新的及时性。另外通过批处理,还有编译优化的一些机制,保证 GPU 的性能和利用率。
第三层是算法模型层,主要封装机器学习与深度学习常见的模型,另外离线开源的训练框架现在有很多,不同框架导出的模型格式各不相同,这方面我们也做了兼容。
接下来从以下几个场景跟大家介绍:多任务多模型、高可用高性能、持续训练持续部署。
模型服务平台现在支持的服务可以归一下类,包括多媒体服务、自然语言服务、排序模型服务。这几类在线服务对于资源的需求是不太一样的,多媒体服务对 GPU 的资源更敏感一些,CTR 这种,CPU 的机器一般情况下就能满足。另外就是多模型,正常来讲,一个在线服务,同一条在线样本,只要过一个算法模型就可以了,有些场景,比如进行多模型的融合,这时同一台样本可能要过多个模型,这种场景可能就需要在有限的机器资源内做一些变化。
为了满足这些需求,我们基于 K8s 做了两件事情,一个是根据资源类型对任务进行了归类,分为 GPU 密集型、CPU 密集型、密集型。像传统 LR/FM 就属于 CPU 密集型; GPU 密集型包括人脸识别、人脸分类、这些卷积神经网络相关的,比较耗 GPU 资源,IO 密集型包括图片下载和视频下载。然后基于不同的类型划分任务组,这个任务组内会整合,这些任务尽量是不同类型的。我们基于 K8s 的 label 机制,把同一个组内的任务调度到同一台、同一批机器上,通过这种方式提高资源的利用率。
在多模型方面,基于现在的在线推理引擎,把多个模型融合在一个服务里面,这样同一条样本,经过一次特征处理,生成的这个模型可识别的格式之后直接过三个模型,通过这个方式提升一定的性能。另外这种多模型的场景,因为不同的业务方模型大小是不一样的,有的模型可能比较小,可能只有几兆,有的模型可能几十兆、几十 G、几百 G,单机可能存不下,我们没法去对所有的服务做统一的资源限制,主要针对业务组进行 ResourceQuota 的机制,这个图展示是目前做到了现在一个数量。
第二个场景,在线 WeiServing 平台很大一部分服务流量来自于推荐系统,推荐系统的一个整体逻辑,简单来看主要包括召回、过滤、粗排、精排、分发控制这几个阶段,可以看到,从粗排、精排这两个阶段来看,推荐系统大约有一千到两千条的物料会调到 WeiServing 里面去,推荐系统服务调用量集在十亿的量,通过放大之后,WeiServing 承担的量一天可能达到千亿级,甚至万亿级,对服务的高可用性要求会更大,而且响应时间也比较敏感。
另外需要说的是,现在推荐系统的每次调用请求,某些场景下有一百多 KB,加上峰值,入流量的带宽可能会达到几百个 GB,所以在线 WeiServing 很大的一个特点就在于服务端的入流量比较大,那么怎么解决高可用和高性能?
首先,我们实现了客户端的负载均衡功能,这里没有使用 K8s 原生负载均衡机制机制, K8s 的负载均衡总体分为两类,不论是 4 层的 Service,基于四层链路的 IPtable 与 IPVS 来实现的,还有基于 7 层链路 ingress,都属于服务端的负载均衡。服务端的负载均衡有很多好处,这里就不一一列举了,它的缺点对于我们来说就是加长了一个网络链路,转发会引起一定的性能损耗,另外在入流量比较大的时候,proxy 可能会成为瓶颈,这张图显示的是早期我们用 LVS 做负载均衡,某个业务扩张了 30%,proxy 网卡将近被打满。
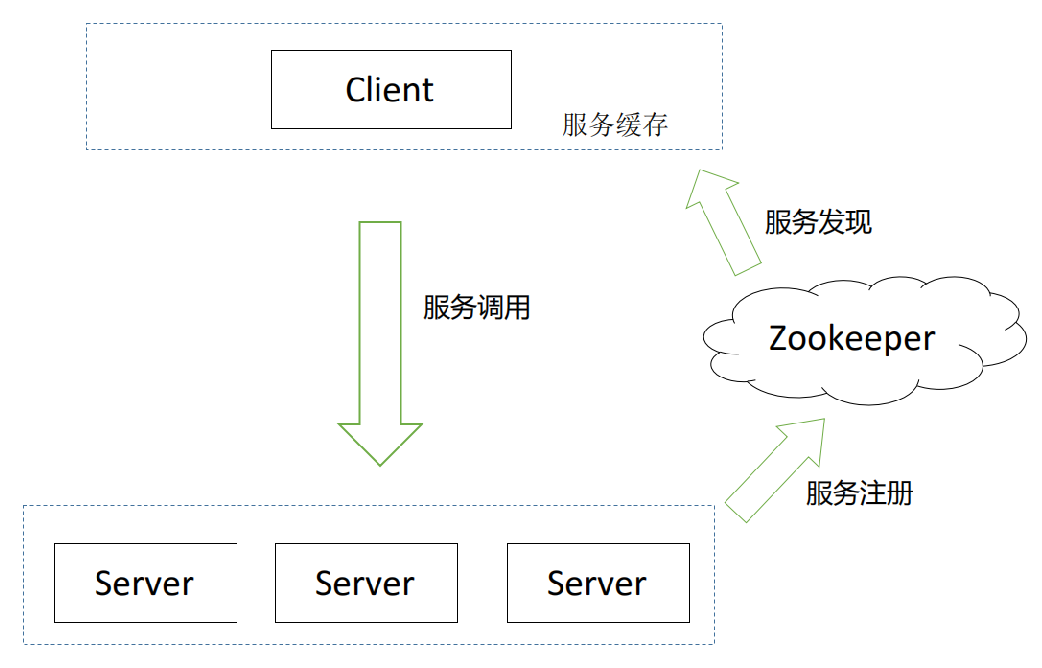
基于这些原因,我们选择了客户端负载均衡。客户端负载均衡,第一是直连,性能服务有保障;第二就是大的入流量情况下,没有单点的瓶颈,任一结点故障,不会影响到整个系统的性能。客户端的负载均衡实现也比较简单,大同小异,这块基于 Zookeeper 做的服务发现,客户端做了一个缓存。我们的在线集群是一个异构的集群,CPU 核数不一样,每台机器的处理能力也不一样,这里服务端做了一些动态的权重调整,保证异构集群的性能稳定。
另外,基于 K8s 的探针模式实现了服务的健康检查,服务上线之后,通过执行业务自定义的健康检查命令进行检查 Pod,如果这个 Pod 失效,我们会将这种无状态的服务进行重启。业务方上线的这些服务,因为它的特征处理不一样,算法模式也不太一样,有的是分类模型,分类模型有得分就可以了,对于回归模型,它需要一个连续的得分,所以在线服务有效性校验这一块需要业务去自定义,我们是通过 initContainer 去加载业务自定义的健康检查插件。
关于优化,深度学习预测的优化主要分为两部分,一个是计算的优化,一个是通讯的优化。
在优化的时候,会经常听到一个阿姆达尔定律,它主要是讲优化的投入产出比,针对链路里耗时最长的阶段进行优化,是投入产出比是最高的选择,在我们这里也比较适用。
列了两个比较有效果的优化点,首先是 batching,batching 有一定的应用条件,GPU 的 batching,如果是调用量比较小,做 batching 可能对性能影响比较大,但是在线 QPS 比较高的情况下,做 batching 的效果是非常好的,它跟 GPU 的利用率有关。
其次,我们在做 CTR D&W 模型的时候,发现有的业务模型会特别慢,经过 Profiling 之后,发现主要耗时在 onehot 编码处理,TensorFlow 这一部分原生使用 Eigen 的线性计算库,这部分重写 onehot 之后,性能提交效果比较明显,这是实践的效果。
最后一个场景就是持续训练和持续部署(CTCD),对于推荐排序的业务场景来说,当模型稳定的时候,持续训练持续部署是一个基本的业务需求。当模型更新的时间周期比较长时,它的在线样本跟离线样本的分布会有比较大的差异,尤其是像微博这样一个产品场景,经常有热点流量,有不可预知性,这种样本分布在线、离线的差异在微博更加明显。第二就是 CT/CD 带来的好处,可以及时捕获用户短期行为的兴趣,快速反馈当前用户感兴趣的内容。
基于这些背景,我们看下持续训练持续部署的流程,简单来讲,首先是模型训练,包括实时训练与离线训练生成的模型会放在模型库里面,模型验证阶段会从模型库拿到模型,进行离线的指标验证,部署到线上,再做一个线上的指标验证,部署时会做一个灰度的发布,根据需要有些场景需要做蓝绿部署,这样将模型推到线上,进行在线 seriving。
在具体实现部分 ,主要应用有两个重要环节,一个是 基于 cronjob 的周期执行。cronjob 会做两件事情,对离线训练,会周期性地启动,把整个流程拉起来;对于实时训练,因为一直在线上运行,这就需要周期的去 checkpoint。
另外一个环节就是模型部署,在部署时使用的 olsubmit,它封装了 kubectl 与服务配置管理, 提供一键式的服务部署与管理。首先,从模型库里拿到模型数据信息,包括模型文件与特征处理文件,然后从配置中心获取的服务元数据信息、包括需要指定的算法库、用于服务发现的配置、模型版本管理的策略;将模型数据信息与服务元数据信息进行封装,推到服务库里,然后服务库的这些服务,主要用来热升级和服务的部署。基于 K8s deployment 资源对象,部署在线的服务。
以上是今天分享的主要内容,总结来看,基于 K8s 主要做了以下几个事情:
K8s 在微博机器学习平台上的应用,目前处于起步阶段,还有很多的事情可以做。为了更好地将 K8s 应用到平台里,这里有些简单的规划:
第一,离线训练数据本地化。 从目前 K8s 元语去看,它在进行调度时计算跟存储是解耦的,那在离线大规模训练场景中,通讯很有可能会达到一个瓶颈,所以我们计划做一些数据本地化的事情,比如基于 Alluxio 做中间件,用于样本数据的缓存;
第二,基于 K8s 支持更多的模型训练框架;