


在日常工作和学习中,我们经常会遇到需要从PDF文件中提取文字的情况。然而,并不是所有的PDF文件都允许我们直接复制粘贴其中的文字。这时候,我们就需要用到OCR(Optical Character Recognition,光学字符识别)软件,它能将图像中的文字转化为可编辑、可搜索的文本。下面,小编将为大家介绍几款实用的OCR识别软件。


捷速OCR文字识别软件是一款支持多种语言、多格式文字识别的软件,内置的OCR识别功能可以帮助识别PDF文档、截图识别、多国语音识别等。在捷速OCR中,直接导入文档、图片即可识别文字内容,软件的OCR识别功能简单易用。
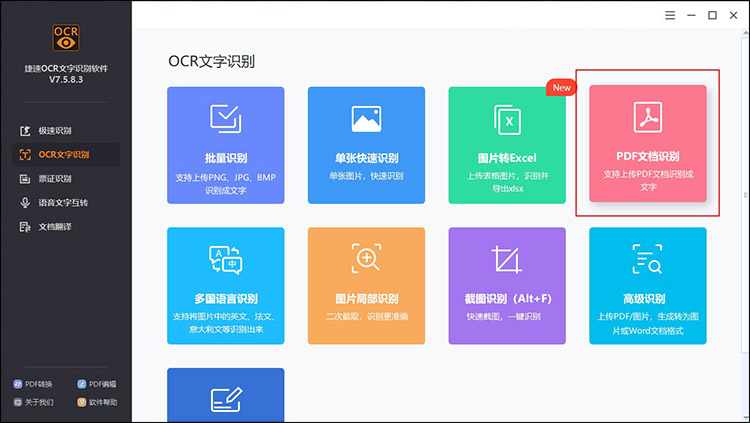
捷速OCR可以将识别的文字导出为可编辑的doc、txt文件。同时,该工具也是支持我们一次性上传多文件进行文字识别工作的。
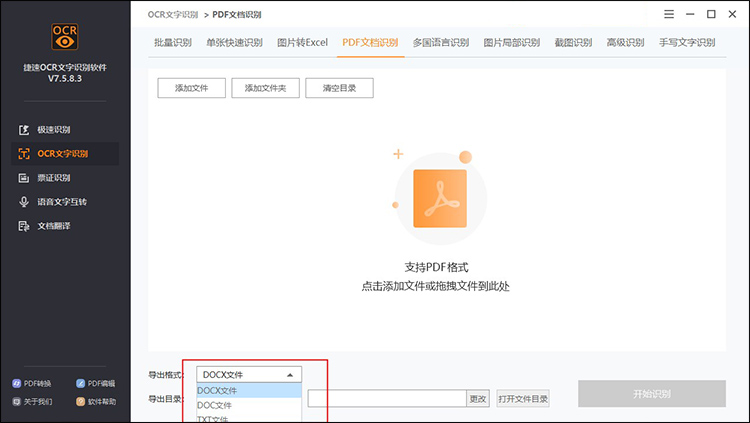
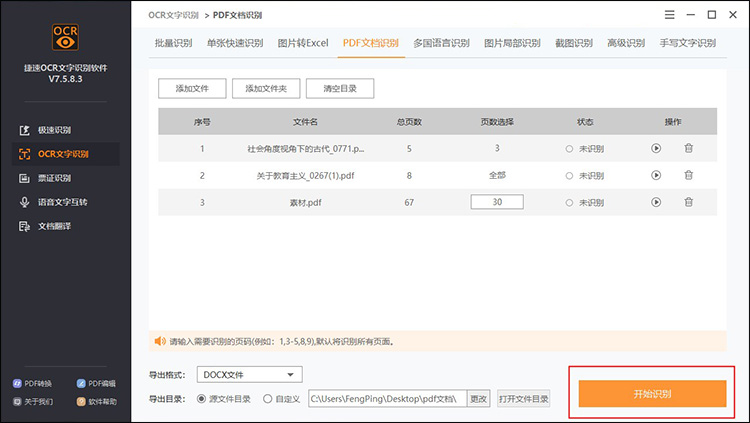
其中,它还可以对PDF文档的页面识别数量进行调整,设置好这些基础的操作之后,点击【开始识别】捷速OCR即可对我们的PDF文件进行文字识别啦!
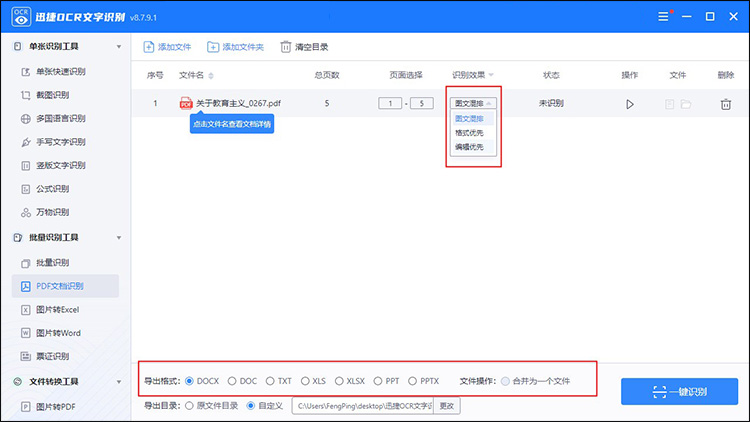
迅捷OCR文字识别是一款专业的OCR识别软件,它不仅支持PDF文件,还能处理图片、扫描件等多种格式的文档。迅捷OCR文字识别的OCR识别准确率非常高,特别是在处理复杂文档和手写字体时表现尤为出色。此外,它还支持多种语言的识别和文本导出功能,非常适合需要处理多语言文档的用户。
Adobe Acrobat也是一款功能强大的PDF编辑和处理软件,它也内置了OCR功能。使用Adobe Acrobat进行OCR识别非常简单,只需打开PDF文件,选择“增强扫描的PDF”或“识别文本”功能,软件就能自动将图像中的文字转化为可编辑的文本。Adobe Acrobat支持多种语言和复杂的文字布局,识别准确率较高。

Tesseract OCR是一款开源的OCR识别引擎,它支持多种操作系统和编程语言接口。虽然Tesseract OCR本身没有提供图形用户界面(GUI),但有很多第三方应用都集成了它的功能。Tesseract OCR的识别准确率较高,且支持多种语言和文字布局。如果你对编程有一定了解,可以尝试使用Tesseract OCR来开发自己的OCR识别应用。