


转载自文章面试官: 为什么不能轻易修改 serialVersionUID 字段?

阿里巴巴开发手册中,第四章OOP规约的第13条解释如下:
【强制】序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果 完全不兼容升级,避免反序列化混乱,那么请修改serialVersionUID值。说明:注意serialVersionUID不一致会抛出序列化运行时异常。
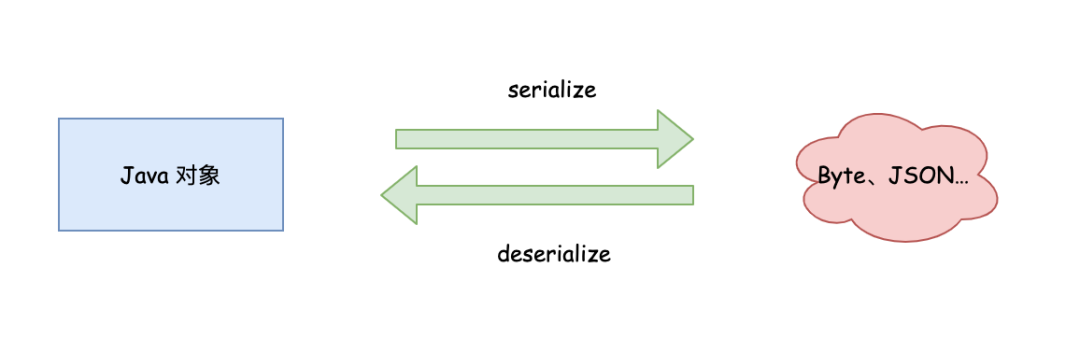
简单来说,序列化就是把不适于存储或传输的数据,转化为另一种形式的数据,使得数据能够得以保存或传输。相对的,反序列化就是将数据形式转化这个过程逆向进行。
比如说Java对象,就可以序列化为JSON,或者是Byte,也可以是我们的自定义形式,比如key-value形式,如下图。
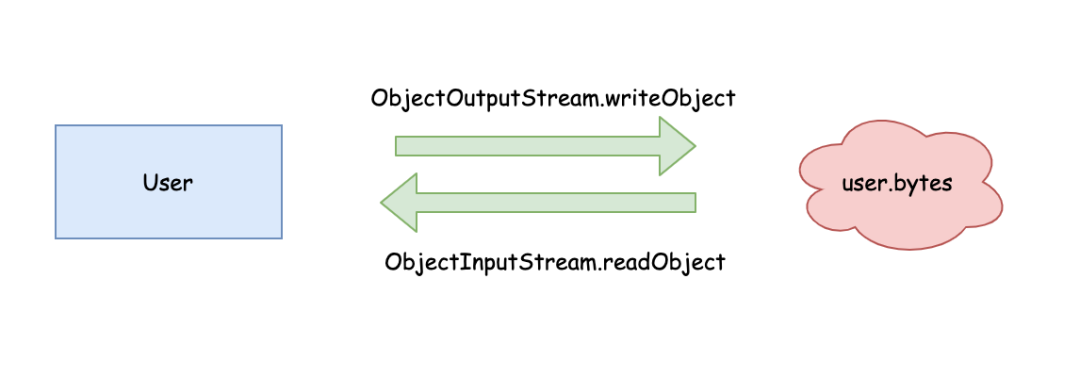
在Java中,默认提供了一种序列化方式。就是对应类实现java.io.Serializable 接口,就可以做到序列化和反序列化。下面分别是实现序列化的类User和测试类SerializerTest。
实现了Serializable接口的User类通过ObjectOutputStream转化为字节码存入user.bytes,再使用 ObjectInputStream把字节码从user.bytes读入内存。
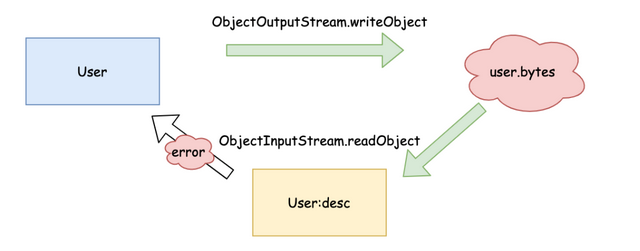
在Java中,类的serialVersionUID用于验证序列化和反序列化的类的版本是否一致。为何不能轻易修改serialVersionUID?调整一下例子,再测试一次。
首先使用UserSerializeTest类对上一节例子中的User类进行序列化,存储到user.bytes中。
随后对User类进行修改,增加一个新的变量desc。使用UserDeserializeTest类对user.bytes进行反序列化,生成User类对象。
执行结果如下。报错显示serialVersionUID不同,反序列化失败。但是代码中并没有定义serialVersionUID,原理是什么呢?
在java.io.ObjectStreamClass#writeNonProxy中,如果当前类没有定义serialVersionUID,就会调用java.io.ObjectStreamClass#computeDefaultSUID生成默认的序列化唯一标识。代码中生成唯一标识的规则是根据类名,接口名,方法和属性等参数生成的hash值,所以给User添加了desc属性,对应的serialVersionUID肯定会变化。
JVM规范里也有具体的解释:
The stream-unique identifier is a 64-bit hash of the class name, interface class names, methods, and fields.
在上一节例子场景中,只要给User类定义一个serialVersionUID,即使在序列化后对User类进行修改,再进行反序列化,也可以成功执行代码。代码如下: