


我要把人生变成科学的梦,然后再把梦变成现实。——居里夫人

关键词是代表文章重要内容的一组词,在文献检索、自动文摘、文本聚类/分类等方面有着重要的应用。现实中大量的文本不包含关键词,这使得便捷得获取文本信息更困难,所以自动提取关键词技术具有重要的价值和意义。
关键词提取分类
有监督虽然精度高,但需要维护一个内容丰富的词表,需要大量的标注数据,人工成本过高。
无监督不需要标注数据,因此这类算法在关键词提取领域应用更多。比如TF-IDF算法、TextRank算法和主题模型LDA算法等。
TF-IDF(Term Frequency - Inverse document Frequency)是一种基于统计的计算方法,常用于反映一个词对于语料中某篇文档的重要性。
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse document Frequency)。TF-IDF 的主要思想就是:如果某个词在一篇文档中出现的频率高,也即 TF 高;并且在语料库中其他文档中很少出现,即DF低,也即IDF高,则认为这个词具有很好的类别区分能力。
TF 为词频(Term Frequency),表示词 t 在文档 d 中出现的频率,计算公式:
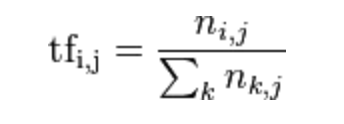
其中,分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
IDF 为逆文档频率(Inverse document Frequency),表示语料库中包含词 t 的文档的数目的倒数,计算公式:
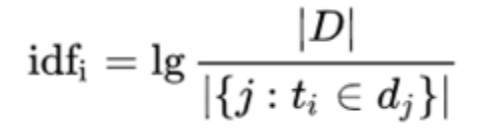
其中,|D|:语料库中的文件总数,|{j:ti∈dj}| 包含词 ti 的文件数目,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用 1+|{j:ti∈dj}|。
然后再计算TF与IDF的乘积:
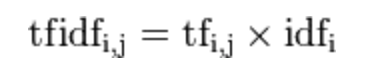
因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。比如:有些词“的”,“了”,“地”等出现在每篇文章中都比较多,但是不具有区分文章类别的能力。
TextRank算法脱离语料库,仅对单篇文档进行分析就可以提取该文档的关键词,此算法最早应用于文档的自动摘要,基于句子维度的分析,利用TextRank对每个句子进行打分,挑选出分数最高的n个句子作为文档的关键句,以达到自动摘要的效果。
TextRank基本思想来源于Google创始人拉里·佩奇和谢尔盖·布林1997年构建的PageRank算法。核心思想将文本中的词看作图中的节点,通过边相互连接,这里就形成了图,不同的节点会有不同的权重,权重高的节点可以作为关键词。
PageRank思想:
TextRank用PageRank的思想来解释它:
公式如下:
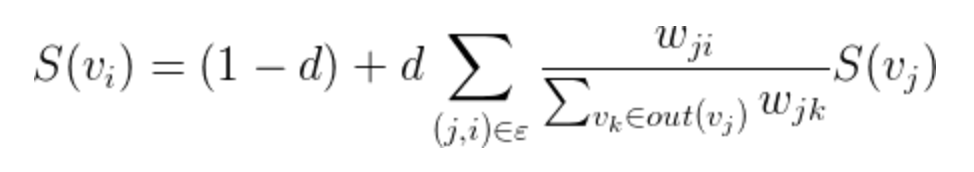
TextRank中一个单词i的权重取决于在i相连的各个点j组成的(j,i)这条边的权重,以及j这个点到其他边的权重之和,阻尼系数 d 一般取 0.85。
TextRank关键词提取步骤:
大多数情况,TF-IDF算法和TextRank算法就能满足,但某些场景不能从字面意思提取出关键词,比如:一篇讲健康饮食的,里面介绍了各种水果、蔬菜等对身体的好处,但全篇未显式的出现健康二字,这种情况前面的两种算法显然不能提取出健康这个隐含的主题信息,这时候主题模型就派上用场了。
LDA(隐含狄利克雷分布)是由David Blei等人在2003年提出的,理论基础为贝叶斯理论,LDA根据词的共现信息的分析,拟合出词——文档——主题的分布,进而将词、文本都映射到一个语义空间中。
- jieba也已经实现了基于 TextRank算法的关键词抽取,如下:
- 通过 Gensim 库完成基于 LDA 的关键字提取,如下: